Introduction
Paxos is one of the oldest, simplest, and most versatile algorithms in the field of distributed consensus. It has long been considered the gold-standard in this domain and dozens of papers and articles have been written to describe its various applications, optimizations, and usage techniques. However, despite the volume of literature that has been generated on this subject in the last two decades it still has a reputation for being particularly difficult to understand and implement.
There are a number of reasons for this but perhaps the most significant is that the existing literature on the subject serves as a terrible entry point for most individuals. The vast majority of papers on the topic are either too specific, being targeted at narrowly-defined, research-oriented topics, or are overly generic where the details of Paxos tend to be obscured by the inclusion of additional and unrelated topics. In aggregate, all of the necessary information for understanding Paxos is readily available but the important pieces are scattered across an array of sources with the end result being that they are effectively hidden, even from astute readers. Moreover, most of the relevant papers are targeted towards an academic audience. It takes a certain kind of mindset to easily process that kind of content and what is easy for professional academics to understand is not necessarily easy for everyone else.
For example, consider the following excerpt from one of the most well-known papers on the subject: Leslie Lamport’s Paxos Made Simple (which, incidentally, claims to explain Paxos in “plain english”):
P2c . For any v and n, if a proposal with value v and number n is issued, then there is a set S consisting of a majority of acceptors such that either (a) no acceptor in S has accepted any proposal numbered less than n, or (b) v is the value of the highest-numbered proposal among all proposals numbered less than n accepted by the acceptors in S.
Lamport is undeniably brilliant, however decades of living and breathing distributed algorithms has apparently skewed his definitions of “simple” and “plain english”. Paxos Made Simple is an excellent paper and is certainly required reading for anyone interested in gaining a firm handle on the topic. Though for anyone other than a hard-core academic with a particular penchant for algorithms, it should be considered a resource for rounding-out one’s existing understanding of Paxos rather than as an entry point for gaining an initial one.
The intent in the following pages is to fill the gap in the existing Paxos literature by providing that initial understanding. The following sections outline the algorithm and explain how and why it works, in practical terms, without an overly pedantic focus or conflating the issues with unrelated topics. The purpose is to instill an intuitive understanding of Paxos in the reader and to demystify the aspects of the algorithm that, traditionally, have been either ignored or left as exercises to the reader.
The most important details for a solid understanding of the core Paxos algorithm and how it fits into the overall ecosystem of distributed computing are covered here but that coverage, by necessity, is incomplete. The overall subject is far too broad for anything short of a full book to reasonably describe and excellent materials covering those subjects are already available. The goal is to provide readers with the background needed to make understanding that existing content a bit easier.
The following sections describe Paxos at three levels of detail. The first provides a high-level overview of what Paxos is and the niche it fills in the distributed systems field. The second section explains how Paxos works and walks through a detailed conflict resolution example to illustrate the key points. The third, low-level description, focuses on the constituent components of the algorithm and explains their roles and responsibilities. Following the description of the algorithm itself, a few sections are dedicated to describing Multi-Paxos, one of the most popular use cases for Paxos.
One point to note is that the following sections use somewhat different terminology from that of the traditional Paxos literature. The reason for this is that, although the original terminology is essentially ideal, many of the terms are overloaded in the existing works and mean different things depending upon the particular paper being read. The terms used here have a one-to-one correlation to the existing terminology but use a unique set of names to reduce the potential for confusion. Transitioning to the standard terminology should be relatively painless once the basics are understood.
High Level Overview
What it Is
The first step in understanding Paxos is to gain a firm grasp of exactly what Paxos is and, equally as important, what Paxos is not. The existing body of literature on the subject is somewhat confusing in this regard as there is a strong tendency for authors to blur the lines between the algorithm itself and the particular use-cases about which they are writing. The unfortunate consequence of this is that it suggests to many readers that Paxos is much more complex than it really is. Simply stated though, Paxos is about one thing and one thing only:
Paxos is a mechanism for achieving consensus on a single value over unreliable communication channels.
The original definition of Paxos additionally included a description of how multiple values could be reliably and efficiently chained together. This is but one potential application for the fundamental, single-value algorithm though so to assist in distinguishing between the two concepts, the term “multi-paxos” emerged over time to refer to the chaining use case while “Paxos” was left to refer to the fundamental algorithm. Some of the existing literature distinguishes Paxos from Multi-Paxos and some does not so care is required to when reading other works to determine which terminology the author is using. Here, “Paxos” refers only to achieving consensus on a single value.
Role in Distributed Systems
The role of Paxos in distributed systems is similar to that of Compare-And-Swap (CAS) in concurrent, single-machine systems. It’s a primitive; a building block upon which higher levels of abstraction may be constructed. It is also completely independent of use cases. Just as CAS is not inherently “for” mutexes or reference counts, Paxos is not “for” replicated state machines or distributed locking. It is a general-purpose tool with many potential applications.
How it Works
The algorithm defines a peer-to-peer consensus protocol that is based on simple majority rule and which is capable of ensuring that one and only one resulting value can be achieved. No peer’s suggestions are any more or less valid than any other’s and all peers are allowed to make them. Unlike some other consensus protocols, there is no concept of dedicated leaders in Paxos. Any peer may make a suggestion and lead the effort in achieving resolution but other peers are free to do the same and may even override the efforts of their neighbors. Eventually though, a majority of peers will agree upon a suggestion and the value associated with that suggestion will become the final solution.
Failure Tolerance
To ensure that consensus can be reached even when some of the peers fail, all peers share equal responsibility for ensuring that consensus is eventually reached. There are multiple steps that must be taken to achieve consensus and the other peers are expected to step in and drive the resolution process forward should the initial driving peer go silent before finishing the required work. This makes Paxos resilient against normal failures such as machine crashes and network outages. Paxos is not, however, resilient against malicious or misbehaving peers. Correctness is guaranteed only if each peer adheres to the protocol requirements.
Incomplete Specification
Paxos places a few specific rules on how peers must handle messages in order to ensure correctness of the end result. The basic algorithm does not, however, provide a comprehensive definition for message handling. There is a surprising amount of flexibility allowed in this regard and it leaves several areas of practical importance completely undefined. For example, it provides little guidance on how failed nodes are to be detected or how collisions between multiple peers making simultaneous suggestions should be handled. The algorithm guarantees correctness irrespective of implementation choices made in handling these issues but offers no clues about how to do it.
The lack of specifics can present a problem to newcomers in that it can make Paxos seem somewhat amorphous and intangible. Later sections attempt to solidify the following important but undefined areas by covering specific techniques that may be used to address them:
- The retry mechanism used to ensure that a result is eventually achieved
- Techniques to mitigate inter-peer interference during resolution
- Ensuring that all peers learn the final result
Benefits of the Incomplete Specification
While a burden to newcomers, the flexibility offered by Paxos can be of tremendous benefit to system designers as it opens up a wide range of potential applications and optimizations. There are a number of tradeoffs to consider when implementing Paxos and although relatively good general-purpose solutions do exist, achieving the best performance typically requires implementation techniques that are tuned to the needs of the application and its operational environment. For example, some implementations may choose to decrease the latency needed to detect and recover from peer failures at the cost of increasing network traffic while other applications may choose to employ techniques that halve the overall latency of a chain of paxos instances. Some may do both or may even use adaptive techniques that respond to the changing behavior of network traffic.
Proper Mindset for Understanding Paxos
When setting out to learn any kind of large and complex system the focus is initially directed toward the abstract components and the interactions between them. Understanding the details of how those components work becomes important later but, initially, a relatively high-level knowledge of each component’s roles and responsibilities is generally sufficient for understanding the overall operation of that system.
The key to understanding this famously difficult topic is to approach it with a similar mindset. Like a large system, Paxos has identifiable components with well-defined roles and responsibilities. Each of those components can become arbitrarily complex when implemented for real-world use but those complexities can be compartmentalized and need not spill over into the other areas. Specifically, the following areas are completely independent of one another and may be considered in isolation:
- Correctness – As long as the messaging rules are adhered to, correctness is ensured by the algorithm and is independent of all other application considerations.
- Ensuring Forward Progress – The application-defined retry and backoff logic used to ensure that resolution is eventually achieved.
- Learning the Final Result – The application-defined mechanism used to ensure all peers eventually learn the result once consensus has been achieved.
- Latency Optimizations – Optional techniques that can reduce the number of round trips required to achieve resolution under certain circumstances.
- Application-Level Logic – How the application uses the results of Paxos instances
Elements of Paxos
Suggestion IDs
One of the keys to Paxos’ ability to operate over unreliable communication channels is that it assigns a unique ID to each suggestion. The details of what Suggestion IDs are and why they are important will become clear shortly but, for the moment, think of these IDs as functioning in a role similar to that of timestamps. They allow peers to determine whether one message is logically newer than another but they avoid the complexities inherent to consistent, shared notions of time in distributed systems.
A common implementation of Suggestion IDs is a simple integer paired with a “tie-breaker” that is used to ensure uniqueness. The notational convention used here is that IDs are pairs comprised of an integer and the peer’s unique id: e.g. (1, A). The IDs are comparable and to determine which is logically newer the integers are first compared in the normal manner and, should they be equal, the unique id strings are then lexically compared to break the tie. Thus (5,B) > (4,B) > (4,A).
The primary purpose of the IDs is to protect the algorithm from delayed and/or duplicated messages. Paxos uses an exceptionally simple rule for accomplishing this. If the ID of a newly received message exceeds that of the last one processed, process it. Otherwise, silently ignore it. The motivation for ignoring delayed messages isn’t quite as self-evident as it is for duplicated messages and the reason for it stems from resolution being a multi-step process in Paxos. Messages associated with old and out of date steps are not allowed to interfere with the currently active ones.
Messages
Paxos uses five distinct messages for achieving resolution. The following descriptions provide a brief overview of the role of each message and specify the required content.
Permission Request
Achieving consensus in Paxos is a two-step process and the first step is gaining permission from a majority of peers to make a suggestion. Permission Request messages are sent to all peers in order to request permission for making a suggestion with the associated Suggestion ID
Required Content
- Suggestion ID for the new suggestion
Permission Granted
If a received Permission Request contains a Suggestion ID that is logically newer than the last one the peer granted permission for, it will send a Permission Granted message in response.
Required Content
- Suggestion ID of the corresponding Permission Request
- Last accepted Suggestion ID (if any)
- Last accepted Value (if any)
Suggestion
Once a peer has obtained Permission Granted messages from a majority of peers, it may send a Suggestion message to suggest a candidate Value for consensus. Note that Values in Paxos are effectively opaque binary blobs. Applications are free to use any kind of Value they choose.
Required Content
- Suggestion ID of the corresponding Permission Request
- Value
Accepted
If a peer accepts a Suggestion message, it indicates that acceptance by sending a corresponding Accepted message.
Required Content
- Suggestion ID of the corresponding Suggestion
Negative Acknowledgment (Nack)
Any number of conditions can cause messages to be lost, network partitions, faulty network cables, machine crashes, etc. For the sake of simplicity, the algorithm relies upon continual retries of the resolution process with incrementing Suggestion IDs for each new attempt. The theory being that if the peers are silently ignoring messages because the Suggestion ID is too low, the continually incrementing Suggestion ID will eventually become large enough that peers will start responding. This is an elegant algorithmic solution but it leaves a lot to be desired from a practical perspective.
Although they are not technically part of the algorithm, most realistic Paxos implementations will elect to use Nack messages in order to explicitly inform peers that their messages are being ignored and that they will need to increase their Suggestion IDs and retry if they wish to achieve consensus. This allows the ignored peer to immediately take corrective action rather than relying on timeouts, retries, and guesswork to distinguish ignored messages from those lost due to network errors or offline peers.
Achieving Concensus
In order to achieve consensus in Paxos, there are two basic steps that a peer must take:
Step 1: Gain permission to make a new suggestion from a majority of peers.
Step 2: Gain acceptance of that suggestion from a majority of peers.
If two or more peers attempt to follow these steps at approximately the same time, they may conflict with one another and prevent a majority from being achieved at either step. When this occurs, the peers simply increase their suggestion IDs and restart the resolution process. Assuming the implementation employs sufficient measures to prevent continual collisions between peers, such as those described in the section on ensuring forward progress, one of them will eventually complete the second step and arrive at consensus.
Message Handling Rules
Associated with each of the above steps is a message processing rule that must be followed by each of the peers:
Upon receipt of a Permission Request message:
The peer must grant permission for requests with Suggestion IDs equal to or higher than any they have previously granted permission for. In doing so, the peer implicitly promises to reject all Permission Request and Suggestion messages with lower Suggestion IDs. Consequently, requests with IDs less than the ID last granted permission to must be ignored or responded to with a Nack message.
Upon receipt of a Suggestion message:
The peer must accept the Suggestion if its Suggestion ID is equal to or higher than any it has previously granted permission for. Otherwise, ignore the message or respond with a Nack.
Real-world networks are chaotic environments. Network partitions can come and go, messages can be arbitrarily lost, delayed, and/or duplicated, and peers can continually crash and recover. The possible message pattern permutations with even small numbers of peers is enormous and it becomes effectively unbounded as the number of peers grows above a handful. However, strict adherence to the required steps and message handling rules guarantees that any and all scenarios will be correctly handled.
The key to Paxos’ assurance of correctness lies in the interplay between requesting permission to make suggestions and actually making those suggestions. When granting permission for a new suggestion, peers must include the highest Suggestion ID and Value they have accepted, if any, in the Permission Granted message. Once the suggesting peer has received a majority of permission grants and before making its own suggestion, the peer must first examine the previously accepted Suggestion IDs and Values contained in those grants. If any peer has previously accepted a suggestion, the Value of the new suggestion must be set to the Value corresponding to the highest Suggestion ID contained in the grant messages. If and only if no peer has previously accepted a suggestion may the suggester supply an arbitrary Value of their choosing.
Simply put, a peer may suggest any Value they choose if no previous suggestions have been accepted. If previous suggestions have been accepted though, the peer is forced to use the Value associated with the highest previously accepted Suggestion ID. This requirement is the crux of the algorithm’s correctness and walking through a conflict resolution example can aid in understanding why this is the case.
Conflict Resolution Example
The following scenario demonstrates how Paxos achieves correct resolution in the most severe conflict resolution case, that in which two sub-groups with differing proposed values are one peer shy of achieving a majority. This example consists of 5 peers and is preceded by a sequence of events that occur in the following order:
- Peer A gains permission to make a suggestion from (A,B,C,D,E).
- A and B become isolated in a network partition
- A suggests ID=(1,A), Value=Foo
- A and B accept the suggestion
- Peer E gains permission to make a suggestion from (C,D,E).
- D and E become isolated in another network partition
- E suggests ID=(2,E), Value=Bar
- D and E accept the suggestion
The following diagram depicts the resulting situation:

At this point, there are two sub-groups that have accepted differing values, Foo and Bar, and no further progress can be made until connectivity between a majority of peers is restored. When a majority is once again available, there are three possible scenarios:
- Continued attempts to gain consensus on ID (2,E)
- Continued attempts to gain consensus on ID (1,A)
- A new suggestion could be made
Note that in the following descriptions, the peers attempting to achieve resolution send and receive messages to and from themselves in exactly the same manner as they do with the other peers. Driving the consensus process forward does not require special access to local state and treating all peers, including oneself, equally is simpler from both a conceptual and implementation perspective.
Case 1
The simplest case is the first one. Should communication be restored between C, D, and E, consensus can be immediately achieved on the value Bar. E simply needs to ask C to accept suggestion (2,E) and its associated value Bar. Once C has accepted the suggestion id and associated value, consensus has been achieved and Bar becomes the final value.

Case 2
If, on the other hand, communication is restored between A, B, and C it is possible for Foo to be chosen instead. Unlike the previous case though, an extra step is required. When A asks C to accept suggestion id (1,A) and its associated value Foo, C will reject the request. It’s forced to do so because it granted permission for E to make its suggestion of (2,E) in step 2 of the scenario. In granting that permission, C implicitly promised to reject all messages with suggestion ids of less than (2,E).
Upon seeing the rejection of its accept message, A can simply restart the resolution process with a new suggestion id that is higher than (2,E). Doing so with the new suggestion ID of (3,A), for example, would result in permission grants that show that the highest previously accepted suggestion id from the majority of peers is (1,A) and with the corresponding value Foo. Per the Paxos requirement, A would then be forced to use the value Foo when it requests the acceptance of (3,A). Once A, B, and C accept the new suggestion, Foo becomes the final value.

Case 3
As described by the previous two cases, it is possible for either Foo or Bar to be chosen as the final value. What is not possible, however, is for any value other than Foo or Bar to be chosen.
For example, if peer C wanted to suggest Baz as the value, it would be unable to do so since any majority of permission grants would include at least one reference to a previously accepted Foo or Bar. If C were to reestablish communication with A and B, it would be forced to set the value for its suggestion to Foo since the permission grants would specify Foo as a previously accepted value. Should it receive a response from D or E in addition to or instead of A or B, it would be forced to set the value to Bar since (2,E) > (1,A).
Non-Case
In the second case described above where Foo is chosen as the final value, it may seem as though the value could change to Bar once E comes back online. After all, E’s suggestion ID of (2,E) is greater than A’s ID of (1,A) so why wouldn’t E’s value supplant A’s?. The answer is simple but can be easy to overlook.
Recall that the A’s initial attempt to achieve resolution on (1,A) is rejected by C since it had already granted permission for (2,E) and thereby implicitly promised to reject all messages with ids less than (2,E). In response, A restarted the resolution process from scratch with the new and higher suggestion id of (3,A).
When consensus is eventually achieved, it is achieved with (3,A) rather than (1,A). So when E eventually reconnects and resumes the resolution process for (2,E), its messages will be rejected by a majority of the peers. Should E then attempt to restart the resolution process just as A did with a new suggestion id such as (4,E), it will be forced to set the suggestion value to Foo once it analyzes the Permission Granted messages and sees that Foo is the value associated with the highest, previously-accepted Suggestion ID.
Additional Points of Note
The resolution process may continue even after consensus is achieved
If a peer is out of sync with its fellows, it may not realize that consensus has already been achieved and may continue driving the resolution process forward. This is safe and expected behavior. All subsequent suggestions will be forced to select the consensual value so it will remain unchanged.
Paxos guarantees consensus only on the final value
The final value is guaranteed to be consistent but peers may disagree about which Suggestion ID achieved consensus. If, for example, a peer is offline when consensus is achieved, it may never see the Suggestion ID that resulted in the initial consensus. If it later attempts to make a suggestion of its own the final value will remain the same but it will appear to that peer as if its own suggestion was the first Suggestion ID to achieve consensus.
The number of peers must be fixed and known ahead of time
This is required in order to ensure that all peers share the same understanding of what constitutes a majority. Were the list of peers allowed to change, the majority would be a moving target and it would be impossible to reliably determine when it had been achieved.
Paxos does not guarantee that all peers will learn the final value
If a peer cannot be reached during resolution process, it may miss all of the associated message traffic and never learn the final result. The algorithm itself provides no direct mechanism to protect against this situation so, if needed, the problem of ensuring that all peers eventually learn the final result is left to the application. There are many possible solutions but perhaps the easiest, from a conceptual standpoint, is for peers to periodically “poll” for a result by simply requesting permission to make a suggestion, even if they have nothing to suggest. Analysis of the grants may immediately show that resolution has been achieved and, even if not, they may attempt to re-achieve resolution themselves using the discovered value. It will often be easier and more efficient though for applications to use an application-level mechanism to discover and obtain the results for old Paxos instances.
Ensuring Forward Progress
Although the Paxos algorithm guarantees that one and only one final result is possible, it does not actually guarantee that one will ever be achieved. The mechanism used to ensure forward progress is left as an implementation-defined detail. Beyond simply requiring that some kind of mechanism be used, Paxos itself provides virtually no guidance on this subject.
There are two general problems all implementations must overcome to ensure that the resolution process will complete: inter-peer interference and peer failures. Neither of these problems is particularly difficult to solve in the general sense but developing optimal solutions for particular applications can be quite a challenge. There are a number of tradeoffs to consider and the best approach to use depends heavily upon the goals of the application and the environment in which it operates.
A well researched and practical foundation for developing solutions for ensuring forward progress is through the use of failure detectors such as those described in the papers Unreliable Failure Detectors for Reliable Distributed Systems and The Weakest Failure Detector for Solving Consensus. However, failure detectors are a fairly complex subject so the following descriptions are based on much simpler mechanisms that are easy to understand but less performant.
Mitigating Inter-peer Interference
From a mathematical perspective, it’s possible for peers to enter retry patterns that loop indefinitely and prevent resolution from ever being achieved; for example:
- A obtains permission for (1,A)
- B obtains permission for (2,B)
- A suggests (1,A) and is denied
- A obtains permission for (3,A)
- B suggests (2,B) and is denied
- B obtains permission for (3,B)
- A suggests (3,A) and is denied
… repeat infinitely …
In fact, it’s a proven impossibility to absolutely guarantee forward progress in any distributed consensus system that is susceptible to message losses. However, this is one of those technical impossibilities that engineers tend to brush off as a minor curiosity. Perfection may be impossible but “good enough” is certainly achievable.
If only a single peer is attempting to drive the resolution process forward, packet losses and general network chaos can delay reaching consensus but there are no possibilities for loops or other progress-stalling problems. Given sufficient time and peer connectivity, a single, determined peer will eventually achieve consensus. There may be some Paxos use cases for which only one peer can reasonably be expected to do all of the work required for achieving resolution. Such cases will be rare though since they result in a single-point-of-failure model where all progress halts if that critical peer goes offline.
More commonly, all peers will share equal responsibility for driving the resolution process to completion. Though as noted in the infinite-loop example, this opens up the possibility for inter-peer conflicts that can stall or even completely prevent forward progress. Fortunately though, these kinds of conflicts fall within a well-understood class of problems for which there are many off-the-shelf solutions.
One simple and effective way to mitigate the contention issue is to use an exponential backoff approach similar to that used for avoiding collisions on Ethernet networks. Each peer starts with a small retransmit window, say 2 milliseconds or so, that is doubled each time a Nack message is received. Before restarting the resolution process, peers delay for a random amount of time between 0 and the current window size. The randomization prevents synchronized delays which could lead to continual collisions and the continually increasing window size ensures that, no matter how bad the network latency is or how many peers are contending, eventually a peer will receive sufficient uninterrupted time to complete the resolution process.
The main issue with this solution is that it can drive up latencies. If the initial windows are set too small for WAN deployments, for example, the first resolution attempt or two may fail every time, thereby driving up overall resolution latency. Similarly, if it’s set too high the overall resolution latency is artificially increased above where it could be. Developing optimal solutions in this area can be challenging; particularly so if the application operates in environments with constantly changing network latencies such as geo-dispersed systems. Other techniques, such as the previously mentioned failure detectors, may be more suitable for most workloads but if a panacea exists for this aspect of the algorithm, it has yet to be discovered.
Recovering from peer failure
As previously mentioned, all Paxos peers usually share an equal responsibility for ensuring resolution is achieved. This means that if the original driver of the resolution process goes silent before completing the process, the other peers are expected to continue driving the process forward. Exactly how this is accomplished though can have a tremendous impact on the performance.
The straight-forward approach is for all peers to immediately start driving the resolution process forward as soon as they become aware of a suggested value. This, of course, results in the worst possible performance though as each peer must begin with a new Suggestion ID and all of them doing so simultaneously will result in an extreme number of collisions. Assuming a good mechanism is in place to prevent continual inter-peer interference, it will eventually result in resolution but the latency will be dreadful. Fortunately, there is a simple extension to the straight-forward approach that mitigates the worst of its performance problems.
Rather than immediately jumping into the fray, each peer can wait for all current drivers to fall silent before stepping in itself. To do this, each peer tracks the time at which it last received a Permission Request or Suggestion message from one of the other peers and only once the silence duration exceeds a certain threshold will it begin attempting to drive the process forward itself.
Using a single, static value for this threshold is not ideal as all peers would time out more or less simultaneously and the same collision storm would ensue. Instead, and similar to the exponential backoff mechanism, the problems associated with synchronized timeouts may be ameliorated by spreading the timeout values over a window of time rather than using a single, static value. Peers select their timeout value randomly from a range of acceptable values that can be tuned to suit the application environment. Low-latency, LAN-based applications may use a small range such as two to ten milliseconds whereas high-latency, internet-based applications may need to use a ranges as high as two to five seconds.
This approach doesn’t eliminate the possibility of collisions but it greatly reduces their likelihood. Even when they do occur, they will generally involve a relatively small number of peers and the backoff algorithm described in the previous section for mitigating peer interference is well suited to dealing with small numbers of colliding peers.
As mentioned previously, however, there are definite downsides to this approach. If collisions are frequent, performance will likely suffer and the amount of time it can take to resolve collisions is not tightly bounded. Depending upon the application this may or may not be a problem. When tighter performance requirements are in effect or more predictable resolution bounds are needed, a mechanism based on failure-detectors may be used instead.
Constituent Components
Although the previous sections referred to Paxos peers as single entities that are responsible for all aspects of the algorithm, there are actually three distinct and separable roles in Paxos: the Suggester, Voter, and Arbiter (alternatively known as the Proposer, Acceptor, and Learner in the classical literature). Most applications will likely prefer to have each peer perform all three roles for conceptual and implementation simplicity but some specialized applications may benefit from splitting the roles apart.
For example, a requirement of the Voter is that it must write to stable storage prior to sending each Permission Granted and Accepted message. This is by far and away the biggest performance bottleneck for most implementations so a high-performance cluster could opt to implement the role of the Voter on top of dedicated embedded devices with fast network interfaces and large amounts of non-volatile RAM. Such devices would likely be able to provide far higher throughput rates and uptimes than traditional servers.
In addition to providing system design flexibility, the distinction between the roles is also directly applicable to the implementation of the algorithm. The roles define clear separations-of-concerns that map perfectly to individual classes with a minimum set of methods. The classes may be used independently to implement any one of the roles in isolation or may be composed into a single class that performs all three roles.
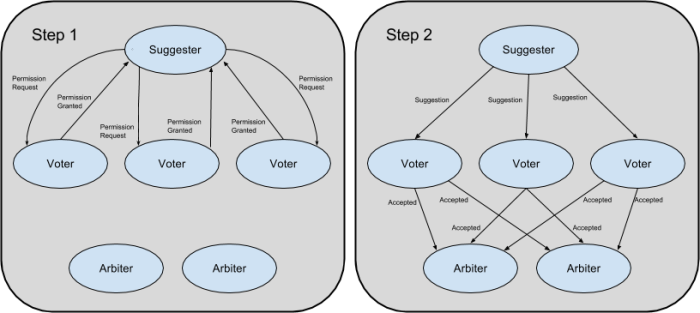
Suggester
The role of the Suggester is to drive the resolution process to completion. It does so via the two step process of gaining permission to suggest a value followed by gaining acceptance of that value. Whereas the other two roles are purely reactive, the Suggester must be proactive and continually work to drive the resolution process forward.
The Suggester has two primary issues to address:
- Handling lost and delayed messages
- Avoiding continual collisions with other Suggesters
As previously mentioned, Paxos does not specify how either of these problems should be solved and the correct approach to use will vary from application to application. Typically these issues are addressed by way of continual retransmits and exponential backoffs, respectively, but those are by no means the only solutions available.
The two-step resolution process for a particular suggestion can fail if another Suggester gains permission to make a suggestion with a higher Suggestion ID before the first Suggester manages to complete the second step. When this occurs, the first Suggester must restart the resolution process with a higher Suggestion ID. Continual retries of the two-step process will eventually result in resolution being achieved as long as sufficient connectivity exists between the peers and an effective solution is employed to prevent continual collisions with other Suggesters.
There is a critical restriction on the Suggester’s ability to suggest Values. If and only if a majority of the received Permission Granted messages contain no previously accepted Values may the Suggester choose an arbitrary Value of their own to suggest. Otherwise, the Suggester must set the Value for their new suggestion to the Value associated with the highest previously accepted Suggestion ID. In simpler terms this could reasonably be described as “If you’re the first one to make a suggestion, suggest whatever you want. If not, go with what the last guy said”. This restriction is the key to the correctness of the algorithm as it ensures that latecomers to the consensus decision will never contradict the decisions made before they arrive. Once consensus on a value is reached, this restriction ensures that it will be forevermore maintained.
An interesting point to note about the Suggester is that although it is responsible for driving the resolution process to completion the Suggester itself is not informed when resolution is achieved. That determination is made by the Arbiter and the protocol does not require that the Arbiter notify the Suggester to tell it that it may stop driving the resolution process forward. Of course, all practical implementations will require some mechanism to prevent Suggesters from running forever but no such mechanism is built into the protocol itself.
Voter
The role of the Voter is to grant or deny permission to make suggestions and to accept or reject those suggestions once they have been made. This is a purely reactive role and it only sends messages in response to requests made by Suggesters. The Voter also provides fault-tolerance for the algorithm. Prior to sending any Permission Granted or Accepted messages, the Voter must store three values to persistent media:
- The Suggestion ID it last granted permission for
- The Suggestion ID it last accepted (if any)
- The Value associated with the Suggestion ID it last accepted (if any)
The correctness of the Paxos algorithm relies upon Voters never forgetting these three values. Recovering from crashes and/or power outages is only possible if these values are stored to persistent media prior to the transmission of each response. Should the Voter crash irrecoverably, it can no longer participate in the resolution process since it will be unaware of any previous commitments it may have made.
When processing a Permission Request, Voters must grant permission if and only if the Suggestion ID for that request is equal to or higher than that of any previous request the Voter has granted permission for. Additionally, the Voter must include its last accepted Suggestion ID and corresponding Value, if any, in the Permission Granted message. If the Suggestion ID of the request is lower than the last request the Voter has granted permission to, the Voter may ignore the request entirely. Typically, however, Voters will send Nacks in response to these messages in order to allow Suggesters to quickly detect and abandon futile resolution attempts. The correctness of the Paxos algorithm does not depend on Nacks but their use typically results in much more efficient implementations.
The processing of Suggestion messages is almost identical to that of Permission Requests. The Voter must accept the Suggestion if and only if its Suggestion ID is equal to or higher than that of any previous request the Voter has granted permission for. The Accepted messages sent in response to accepted Suggestions should be sent to all Arbiters and must include the Suggestion’s Suggestion ID and corresponding Value. Strictly speaking, the Value is not required but if it is not sent, the Arbiter will be able to determine that consensus has been reached but it will have no idea what the consensual value is. Also similar to permission request processing, Nacks may optionally be sent when Suggestions are rejected due to having too low of a Suggestion ID.
Arbiter
The Arbiter is purely passive and is the simplest of the three roles. Its sole responsibility is monitoring Accepted messages to determine when a majority of peers have accepted a suggestion and thereby achieved consensus.
Common Pitfalls
Paxos is often criticized as being extremely difficult to implement and use correctly. Individuals and organizations that come to this conclusion generally do so after one or more trial-by-fire exercises in which they attempted to use Paxos to build a complex distributed system and ran into a number of difficult problems while doing so. The resulting frustration with Paxos is understandable but unfortunate since it usually stems from an underlying problem other than the algorithm itself.
If one looks carefully at the common frustrations, the motivating issues generally fall into one of three categories:
- Inherent Complexities of Distributed Systems
- Algorithm Modifications
- Software Design
Inherent Complexities of Distributed Systems
Paxos is a powerful algorithm but it is limited to achieving consensus on a single value. Most applications overcome this restriction by breaking problems down into small, individual decisions that use Paxos to ensure consistency on each. The results of these decisions are then woven together by higher-level logic to accomplish the goals of the application.
Generally speaking, this is a good approach. However, Paxos is not a magical, distributed-system panacea that automatically ensures the correctness of systems built on top of it. While Paxos certainly does guarantee consensus for each individual value, it does nothing to protect system designers from faulty logic in using those values. Similarly, Paxos doesn’t isolate designers from the other intrinsically difficult problems in distributed systems.
For example, while Paxos ensures that only a single value will reach consensus, the algorithm itself does not ensure that all peers will become aware of that value. If any kind of state synchronization between the peers in a system is required, some other non-paxos mechanism must be employed to achieve it. Similarly, if any form of coordination is required amongst peers in using the consensual values, some other means of achieving that coordination is required. For example, using consensus to agree that a node should execute a processing job is a good start but something else must ensure that it happens within a timely manner, is reassigned if the node crashes, that the results are properly reported, etc.
The paper Paxos Made Live provides an excellent, real-world description of how these contributing issues can impact a Paxos-based project. In fact, the paper may more appropriately have been titled Replicated State Machines Made Live since Paxos itself is ignored and the focus is placed entirely upon the practical complexities involved in maintaining consistent, replicated logs and state machines. Implementing Paxos correctly for achieving consensus on individual rounds gave the team behind the paper little trouble but building a production-quality, distributed system on top of it required solving a number of difficult problems that had little to do with consensus. Ultimately, of course, they achieved a robust and stable system but the paper is a good illustration of how doing so can be quite challenging.
Algorithm Modifications
When sitting down to design a system based on Paxos it can often be tempting to modify or extend the core algorithm in some way to seemingly better suit the needs of the application. Such temptations should be avoided though since algorithmic modifications are difficult to do correctly and usually wind up causing more problems than they solve. Instead, designs should be approached from the perspective of the Paxos algorithm being an immutable set of rules that must be strictly adhered to. Those rules are surprisingly flexible though and with a little ingenuity it is possible to overcome most of the problems that would, at first glance, appear to require a change to the core algorithm to achieve.
One of the key flexibilities afforded by the algorithm is that it is capable of tolerating any combination of dropped or delayed messages. This is particularly important as it is often possible to address application-level issues by converting them into problems that can be solved by intentionally dropping, delaying, and/or injecting messages into the unmodified algorithm. For example, the section below on multi-paxos describes a message dropping and injecting technique that can be used to skip the first step of Paxos’ normal two-step process. This allows resolution to be achieved in a single network round trip during normal operation and provides a major latency and throughput benefit for multi-paxos systems without requiring any changes to the core algorithm.
As long as the required messaging rules are not violated, the proven correctness of the core algorithm ensures that any mechanism based on this approach is similarly guaranteed to be correct. It does not ensure that forward progress can be made under any and all circumstances but detecting, diagnosing, and repairing stalls is significantly easier than doing the same for errors in correctness.
Of course, there are some absolute limitations of Paxos that cannot be overcome without modification. Generally speaking though, those limitations are related to performance considerations for particular use cases and are not limitations with respect to how the algorithm may be leveraged. A later section discusses some of the augmented Paxos protocols and provides an overview of their motivating concerns and how the algorithmic changes address them.
Software Design
The evidence seems to suggest that there is something about Paxos that acts like kryptonite to experienced software developers. Scanning through open-source software that uses Paxos quickly demonstrates that it is almost universally implemented with poor encapsulation and/or separation of concerns. The algorithm’s logic is typically spread throughout the application and, in those few instances in which it is isolated to a dedicated set of classes, the logic tends to be littered with low-level networking concerns. It is as though the basic rules for software design somehow go out the window when it comes to implementing this particular algorithm.
Implementations that fail to tightly encapsulate the algorithm and isolate the networking considerations inevitably result in complex code that is difficult to understand, debug, and maintain. Given the apparent prevalence of such implementations, it is small wonder that Paxos has garnered a reputation of being difficult to implement and use. Even if the other two common pitfalls with Paxos are avoided, the frustrations involved with battering inherently error-prone implementations into shape is enough to fray the nerves of even the most experienced developers.
The solution to this is to revisit software design principles and ensure they are applied to the implementation. Paxos implementations should consist of a small set of classes that implement the core algorithm and nothing else. Even though Paxos is all about the sending and receiving of messages, actual implementations achieve the greatest flexibility and best separation of concerns when messaging is ignored entirely. Each message reception can be modeled simply as a method call with the message’s content as the arguments and each response message can be modeled as a returned object from the corresponding receiver method. Instances of these tightly-constrained, opaque classes then become the foundation upon which the application-specific logic and networking strategy is based.
Multi-Paxos
Paxos is a powerful tool but it is of rather limited utility on its own. Few software systems require consensus to be reached only once so Paxos is typically used multiple times within an application. The results of each instance of the algorithm are then woven together by application-level logic into a cohesive result. There are many ways in which this can be done but a simple, sequential chain of instances is surprisingly powerful and is easily the most popular method.
Just as there are many ways in which the core Paxos algorithm may be used, there are also many ways in which a chain of paxos instances may be implemented. No one approach is ideally suited for all applications so the term Multi-Paxos refers to the general use case rather than to a specific design or implementation. The primary reason for the interest in multi-paxos is that it is exceptionally well suited to maintaining the consistency of shared data and a sizeable portion of the existing Paxos literature is dedicated specifically to this subject.
As the following sections demonstrate, multi-paxos can be used to implement consistent, replicated logs over a cluster of machines. Although this may not sound like much, it is actually an extremely important use case and it is the reason why multi-paxos has received so much attention.
Note: Diego Ongaro recently developed Raft as an alternative to multi-paxos for maintaining replicated logs that provides similar capabilities at reduced complexity. Although Raft does not provide quite the same level of flexibility as multi-paxos, it is very good at maintaining replicated logs and has received much acclaim for being easier to understand and implement correctly.
Implementing a Replicated Log
In addition to being one of the most important use cases for multi-paxos, replicated logs are also one of the simplest things to construct with multi-paxos. Log files are used in an append-only manner so a unique Paxos instance may be used to ensure that all peers agree on the outcome of each append operation. If all peers start with an empty file and they all agree on the exact order and content of every append operation, the file will remain identical across all of the peers.
Conceptually, it is a fairly straight-forward idea. However, when it comes to implementation, there are a number of problems to solve:
- How will messages from different Paxos instances be prevented from interfering with one another?
- If a peer misses one or more append operations, how does it detect this?
- How do peers catch up when they fall behind?
- How can a peer know if it has the most up-to-date version?
The first two problems are easily solved by using the length of the file to identify which Paxos instance the messages belong to. The file size can only increase as a result of the append operations so its current value uniquely specifies the Paxos instance required for the next update. Assuming each operation appended twenty five bytes, the first, second, and third Paxos instances would be identified as 0, 25, and 50, respectively.
Upon receipt of a message and before anything Paxos-related is even considered, each peer looks at the file length embedded in the message and compares it to the length of its own file. If the lengths match the two peers are in sync and processing of the message continues normally. If they differ, however, Paxos processing of that message is skipped because one of the peers has fallen behind. If the receiver’s current length is greater, the sender is behind and may be informed of this via a special Nack message. If the receiver’s current length is less, the receiver has fallen behind and must catch up.
Once a peer realizes it has fallen behind, the third problem of catching up is quite easy to solve. All it needs to do is request the missing bytes from an up-to-date peer. When the local copy of the file is updated and its size matches that of the rest of the peers, it may once again participate in the resolution of the Paxos instances.
The fourth problem comes into play when application-level logic wants to make use of data contained in the log and needs to be sure that the data it is reading is completely up-to-date. The difficulty stems from the fact updates to the log can occur without all peers being aware of them. Dropped and/or delayed messages can cause peers to temporarily fall behind so, as a consequence, no individual peer has enough information to guarantee that its copy of the log is completely up-to-date. To answer the question of whether a particular peer’s log is current, consensus must first be reached on the what the current version is. Once this is known, the peer can fetch any missing data and respond to an application-level read request with data that is guaranteed to be current.
Replicated State Machines
The reason multi-paxos and, more specifically, the creation and management of replicated logs has received so much attention is that they provide a solid foundation for building Replicated State Machines. Replicated state machines are based on the same principle underlying replicated logs but are generalized to arbitrary data structures. If all machines exactly agree on the sequence and content of each instruction used to modify some arbitrary data structure, that data structure will be consistently replicated across all of those machines. For example, a replicated key-value database could be implemented in terms of modification instructions that contain operations such as “insert foo=bar” and “delete baz”.
Knowing what replicated state machines are and how they’re implemented is nice but the reason they’ve received so much attention probably isn’t immediately obvious. The main benefit they provide for distributed applications is that they serve as a convenient abstraction above the low-level consensus protocols for coordinating distributed systems. Rather than dealing with low-level primitives, applications can be written against high-level data structures that support atomic, pass/fail updates. The simplistic, transactional model this abstraction provides makes distributed application design significantly easier.
All replicated state machines must overcome the same set of problems described for replicated logs; detecting they’ve fallen behind, catching up, and so on. These problems are relatively easy to solve for replicated logs so rather than developing custom solutions to these issues over and over again for each new type of replicated state machine, most replicated state machines are implemented in terms of a replicated log. The modification instructions for replicated state machines implemented this way are simply serialized and appended to the end of the log. Each peer then reads the instructions out of the log and updates their copy of the shared data structure.
Performance Considerations
Straight-forward implementations of replicated state machines built on top of multi-paxos suffer from two major performance limitations. One limitation affects writes and stems from the fact that Paxos requires a minimum of two round trips over the network (ignoring client/server communication) in order to achieve resolution. As a consequence, the addition of each link to the multi-paxos chain also requires two round trips over the network. This makes writes fairly expensive operations with relatively high-latency and low throughput.
The other limitation affects reads and stems from the fact that any peer can add links to the multi-paxos chain at any time. Because peers can fall behind one another, all read operations must first use a full Paxos instance to gain consensus on what the most recent state is before they can return a result that is guaranteed to be up-to-date. This makes reads equally as expensive as writes.
The ideal situation would be for write operations to require only a single round trip over the network and for read operations to be serviceable purely from the local state. Although the straight-forward implementation cannot support this, it turns out that both of these goals are achievable if the ability to add links to the multi-paxos chain is restricted to a single peer.
Master Peers
These so-called master peers can optimize both read and write performance by applying techniques that rely upon the inability of other peers to update the multi-paxos chain. The benefit for reads is fairly straight-forward. Because no other peer is capable of updating the multi-paxos chain, all writes must go through the master. Consequently, its local copy of the shared state is guaranteed to be the most recent so it may directly respond to read requests. For writes, the benefit is a bit less obvious but a message injection technique may be used to reduce the number of round trips required for resolution on link additions down to one; assuming, of course, that no messages are lost.
Resolution in a Single Round Trip
The trick to achieving resolution in a single round trip is to avoid the need for the first step in Paxos’ two-step process. When all peers are can agree from the outset on which peer should make the first suggestion, there is no need to actually send the Permission Request and Permission Granted messages across the network. Instead, each node can locally generate those messages and inject them into their Paxos implementations.
To demonstrate how this works, consider a muti-paxos chain where each link in the chain is a pair consisting of (next_master_uid, link_value), exactly how the master peer is chosen and maintained is discussed later but for the moment assume that one has already been determined. All peers agree on which peer is the master for the next link so they may generate and process a Permission Request with Suggestion ID (0, master_uid) for that link as if it came from the master. Similarly, the master peer may generate and process Permission Granted messages for that Suggestion ID as if they came from all other peers. In the failure-free case, the Paxos instance then takes only a single round-trip to complete as only the Suggestion and Accepted messages for Suggestion ID (0,master_uid) need to be sent over the network. The end result is identical to that of actually sending the Permission Request and Permission Granted messages over the network but latency associated with them is completely avoided.
This general approach for reducing the round trips is correct as long as all non-master peers that attempt to achieve resolution in the master’s absence do so by beginning with Suggestion IDs greater than (0,master_uid). The normal two-step mechanism is used for all suggestions following the first so the master’s initial Suggestion ID must be the lowest.
Bypassing the Permission Request and Permission Granted messages is only possible for the first suggestion in a Paxos instance so when the master goes offline or errors are encountered, the normal two-step resolution process resumes. On healthy networks though, the first suggestion will almost always succeed so the average latency for link additions will be that of only a single round-trip across the network.
Write Batching
Beyond simply lowering client response times, the reduced resolution latency offered by this approach also improves write throughput since more links in the multi-paxos chain may be added in the same amount of time. Dedicated masters can further optimize write throughput by packing multiple writes into each link in the chain. There is no requirement for a one-to-one correspondence between links in the multi-paxos chain and state modification instructions so each link may contain a list of sequential modifications instead of just a single value. The master may buffer all write requests received while waiting for the current link to resolve and include them all in the value for the next link.
Mitigating the Single Point of Failure
Taking a step back from the details, there is a significant drawback to master peers in that it introduces a single point of failure into an otherwise robust model that can tolerate multiple failures. The problems associated with this single point of failure cannot be entirely eliminated but they can be mitigated by allowing a new master to be elected when the current one fails. The drawback is that read and write operations are completely blocked until the failure of the master peer is detected, the subsequent reelection process completes, and clients are informed of the new master’s identity. In most properly tuned implementations reelections will be rare occurrences so the performance benefits of this approach will usually offset the occasional hiccups in availability.
Master Leases
Multiple approaches exist for implementing dedicated masters in multi-paxos but one of the most prevalent is the use of time-bound ‘leases’ where the peer holding the current lease is the designated master. Master leases are typically short in duration and in order to maintain its master status across lease boundaries the master will continually renew the lease as its expiration time draws near. The tradeoff involved is that shorter lease durations allow for quicker detection of master failures but this comes at the cost of increased network traffic dedicated to lease renewals. False positives also become more likely as the detection thresholds are tightened so there are practical limits on how quickly master failures may be reliably detected. False positive detections do not affect correctness but master transitions are expensive from a performance and availability perspective. Reducing their occurrences down to a reasonable level while still providing acceptable response times to master peer failures may require careful tuning.
Master Lease Implementation Approaches
For the leases themselves, there are two basic implementation approaches to choose from. They may either be managed outside of and in parallel to the multi-paxos chain or they may be managed through the chain itself. As is generally the case, there pros and cons to both approaches but using the multi-paxos chain to manage leases is generally less error-prone. Parallel lease implementations must be especially careful to avoid any possibility of violating the rule that only the master peer is permitted to make changes to the chain while the lease is held. Faulty hardware, clock drift, and misconfigured systems, to name but a few, conspire to make parallel approaches particularly difficult to implement correctly. Using the chain to manage the leases is simpler in that the worst of the timing considerations are avoided but it comes at the cost of somewhat reduced link addition throughput since some of those links must be set aside for managing the leases.
Chain-Based Management of Master Leases
Using the chain to manage leases is accomplished by adding a layer of indirection to the application-level values generated by the chain. Rather than a one to one correspondence between link values and application level values, each value in the chain may instead be a pair of elements in which one of the two elements is always null. The pair may contain either the next application-level value or it may contain a new multi-paxos configuration; but never both. The most recent configuration defines the master peer and the duration of time for which that peer is guaranteed to be the master. The master may suggest configuration changes at any time, and must do so prior to the expiry of each lease in order to continually maintain its master status. In contrast, all other peers, must wait for the lease to expire before suggesting changes.
Master Lease Restrictions on Message Handling
Restricting link additions that contain application-level values to the current master is essential for ensuring that the master’s copy of the shared state is the most up-to-date. To safeguard against non-master link additions, all Permission Request and Suggestion messages originating from non-master peers must be dropped while the master lease is held. This delays recovery from master peer failures but ensures that only the master is capable of making new link additions while the lease is held. When the lease expires, the messaging restriction is lifted and the normal Paxos resolution process resumes. If the master had started but not finished the resolution process for the current link in the chain, the mechanism used to ensure forward progress will result in one of the peers finishing the process for the current link.
Timing Considerations for Master Leases
One practical point of note is that absolute time in distributed systems generally isn’t trustworthy. Even when time synchronization protocols are used, there are many ways in which the clocks on systems can differ significantly from one another. Human errors such as misconfigured synchronization daemons, timezone settings, and firewall rules are uncommon but not unheard of in most environments and there is always the possibility for those rare but real hardware failures that reset the clock of a system to years in the past, years in the future, or anything in between. A good rule of thumb in designing distributed systems is to avoid relying on synchronized clocks for correct operation whenever possible.
To that end, one approach for managing the time associated with master leases is for each peer to use relative durations based exclusively off of their own local clocks. Each peer defines the lease expiration time to be the local time at which they learned of the lease’s existence plus the lease duration. Due to network latencies and variable load on the individual peers, few, if any, peers will precisely agree on the exact lease expiry time in an absolute sense but the critical aspect of the leases, which is preventing a peer from assuming master status before the lease truly expires, is protected.
When attempting to first gain a master lease and also when renewing it, the lease timer is started before the first message to establish the lease is sent. Because there is at least some minimal delay required in achieving consensus on the new lease, the master’s local lease timer is guaranteed to expire before the rest of the peers, thus preventing any window of opportunity in which one of the other peers may gain master status while the current master believes it still holds the lease. Faulty clock hardware on a peer could cause it to think that a lease had elapsed early but this problem is mitigated by the requirement that all peers drop Permission Request and Suggestion messages originating from all non-master peers while they believe the lease is held. As long as a majority of peers do not have similarly faulty hardware, the master’s status is protected.
Handling Master Peer Failures
When the master lease expires, the peers assume that the master has failed and they work together to elect a new one. With chain-based lease management, this is easily accomplished by each peer attempting to update the multi-paxos configuration with itself set as the new master. Regardless of the implementation approach, there should be a quick turn around time on the detection and re-election processes since all read and write operations must be suspended until the new master is established and clients are informed of its new identity. This makes master peer failures fairly expensive operations so graceful transitions where the master preemptively hands off its master status to another peer should be used whenever possible.
Managing Peer Membership Over Time
Most real-world multi-paxos implementations need to support the occasional addition and removal of peers in order to support hardware replacement and changing scaling requirements. Even more so than master leases, this can be exceedingly tricky to accomplish externally since all peers must exactly agree on the peer membership for each link in the chain and any errors here can violate the correctness of the protocol. Consequently, using the chain itself to manage the peer membership list is greatly advantageous since all peers are already in agreement on the content for each link in the chain. When an addition or removal is desired, the updated membership list may simply be entered into the chain and all peers can then use the updated list for the next link in the chain.
Paxos Variants
The following sections provide brief descriptions of a few variations of the original Paxos algorithm.
Fast Paxos
Fast Paxos is a variation of the classical algorithm that allows resolution to be achieved in a single round trip. To support this, Fast Paxos is broken down into fast and classical rounds where multiple peers may simultaneously suggest values in fast rounds and only a single peer may suggest a value in classical rounds. The primary cost of this modification is that fewer failures can be tolerated than in traditional Paxos. Instead of needing a simple majority, n – (n-1)/2, single round trip resolution in Fast Paxos requires a larger quorum of n – (n-1)/3 to agree on a proposal. The modified algorithm is described in the original, brain-bending paper Fast Paxos written by Leslie Lamport as well as in the more easily understandable A Simpler Proof for Paxos and Fast Paxos by Marzullo, Mei, and Meling.
Despite the obvious appeal of being able to achieve resolution in a single round trip, Fast Paxos does not always result in lower latency than classical Paxos. In realistic environments, particularly WAN environments, there does not appear to be a clear winner between Classic Paxos and Fast Paxos. The papers Classic Paxos vs Fast Paxos: Caveat Emptor and HP: Hybrid Paxos for WANs discuss some of the complicating issues.
Generalized Paxos
Generalized Paxos is a performance enhancement over the classic algorithm that reduces write contention on replicated state machines. In traditional multi-paxos, all peers share logs with exactly the same sequence of operations. Each time the log is appended to, a majority of peers must exactly agree on the content of that addition. In Generalized Paxos, the order of the entries in the peer logs are allowed to differ from one another as long as the sequence of operations results in the same end state.
For example, simple insertions to a replicated key-value store do not conflict with one another so they may be applied in any order and the end result will always be the same. Generalized Paxos allows such operations to commit without strict ordering requirements to reduce contention and improve write latency. Some operations, however, do have strict ordering requirements and in those circumstances the operation specifies the required history that must be present in each peer’s log in order for the write to be permitted. Carrying on with the key-value example, deletion operations would require that each peer’s log contain the corresponding insertion in order for the deletion to complete successfully.
Byzantine Paxos
Classical Paxos ensures correctness in the presence of regular network failures but does not protect against intentional attempts to break the consensus protocol. Byzantine Paxos is a variant of the original algorithm that is robust against peers actively attempting to undermine consensus by lying, colluding, fabricating messages, etc. Despite the obvious benefits of being a more secure protocol, it has seen somewhat less general adoption than might be expected. In part this is probably due to the additional expense incurred in the form of an additional message delay and cryptographic overhead. Also, while a malicious peer may not be capable of breaking the consensus protocol, if it is capable of corrupting the application-level values being considered, the point may be moot. Injecting malicious values into a multi-paxos chain, for example, may be just as bad as failed consensus.
Egalitarian Paxos
Egalitarian Paxos is a modification designed to improve the performance of multi-paxos by achieving three main objectives:
- Optimal commit latency over wide-area networks
- Optimal load balancing across all replicas for achieving high-throughput
- Graceful performance degradation when some replicas become slow or crash
Similar to Generalized Paxos, this protocol also leverages non-interference to reduce write contention but it provides several performance benefits beyond what Generalized Paxos alone is capable of.
HP Paxos
HP Paxos is a hybrid protocol that attempts to combine the best aspects of Classical Paxos, Fast Paxos, and Generalized Paxos. It specifically addresses the practical limitations of Fast Paxos that can render it slower than Classical Paxos and uses Fast Paxos only as an optimization when collisions are absent. When collisions are encountered, it falls back to Classical Paxos which performs better under those circumstances. An additional benefit of HP Paxos is that it supports the Generalized Paxos notion of allowing non-interfering writes to commit without strict ordering requirements.
Reference Implementations
In addition to reading papers, perusing functional code and hands-on experimentation can often aid understanding. To that end, a reference implementation of the Paxos algorithm may be found at https://github.com/cocagne/python-composable-paxos. This implementation focuses purely on the algorithm itself and excludes all application-specific logic such as the messaging infrastructure and retry logic. A fully-functional example that includes this additional logic is available at https://github.com/cocagne/multi-paxos-example and is specifically intended for Paxos newcomers to experiment with. As such, it focuses on strong separation-of-concerns so that various strategies for things like conflict avoidance and catch-up logic may be swapped in and out.
References
- Paxos Made Simple – http://research.microsoft.com/en-us/um/people/lamport/pubs/paxos-simple.pdf
- Paxos Wikipedia Page – http://en.wikipedia.org/wiki/Paxos_(computer_science)
- Paxos Made Moderately Complex – http://www.cs.cornell.edu/courses/cs7412/2011sp/paxos.pdf
- Paxos Made Live – http://www.cs.utexas.edu/users/lorenzo/corsi/cs380d/papers/paper2-1.pdf
- How to Build a Highly Available System Using Consensus – http://research.microsoft.com/en-us/um/people/blampson/58-Consensus/WebPage.html
- Fast Paxos – http://research.microsoft.com/pubs/64624/tr-2005-112.pdf
- Classic Paxos vs Fast Paxos: Caveat Emptor – http://www.sysnet.ucsd.edu/sysnet/miscpapers/hotdep07.pdf
- A Simpler Proof for Paxos and Fast Paxos – http://wwwusers.di.uniroma1.it/~mei/SistemiDistribuiti/Schedule_files/fastpaxosfordummies.pdf
- Generalized Consensus and Paxos – http://research.microsoft.com/pubs/64631/tr-2005-33.pdf
- Byzantizing Paxos by Refinement http://research.microsoft.com/en-us/um/people/lamport/tla/byzsimple.pdf
- There is More Consensus in Egalitarian Parliaments – http://css.csail.mit.edu/6.824/2014/papers/epaxos.pdf
- HP: Hybrid Paxos for WANs – http://webmail.deeds.informatik.tu-darmstadt.de/dan/ghp.pdf.old
- Unreliable Failure Detectors for Reliable Distributed Systems – The Weakest Failure Detector for Solving Consensus – http://zoo.cs.yale.edu/classes/cs426/2014/bib/chandra96theweakest.pdf
- Impossibility of Distributed Consensus with One Faulty Process – http://groups.csail.mit.edu/tds/papers/Lynch/jacm85.pdf
- In Search of an Understandable Concensus Algorithm – https://ramcloud.stanford.edu/raft.pdf

Great post thanks. Much easier to understand than any other Paxos description I’ve see so far.
Just one question. You wrote “There is a critical restriction on the Suggester’s ability to suggest Values. If and only if a majority of the received Permission Granted messages contain no previously accepted Values may the Suggester choose an arbitrary Value of their own to suggest. Otherwise, the Suggester must set the Value for their new suggestion to the Value associated with the highest previously accepted Suggestion ID. In simpler terms this could reasonably be described as “If you’re the first one to make a suggestion, suggest whatever you want. If not, go with what the last guy said”.
Is the word “majority” really supposed to be in the second sentence? It seems to contradict the last sentence.
LikeLike
Thanks John. I see what you mean about the apparent contradiction. The last statement is reasonably correct but it’s not very precise and that allows room for confusion. The “majority” reference is definitely intended to be there and the reason for it is that Paxos supports dropped messages. So if, for example, you have a scenario with 5 participants, say ABCDE, and only D & E are aware that a previous suggestion of “foo” had been made, it would be possible for A to see that a majority of peers agree that no suggestions have yet been made (say D&E went offline right after hearing about “foo” and the messages to ABC were lost). It’s a fairly subtle but important distinction; this kind of stuff regularly occurs on real-world networks.
I also mention in a section further down on in the paper that it’s possible for a peer to intentionally ignore messages under certain circumstances. If peer A really, really wanted to suggest it’s own value and it receives responses from all of the peers. It could choose to “drop” the responses from D & E. It’d then be left with a majority of peers that have not seen a previously suggested value and would be free to suggest whatever value it wants; all in complete accordance with the algorithm. On occasion, the protections against dropped and duplicated messages can be used to your advantage when designing an application.
LikeLike
Thanks for your reply. I still haven’t quite “got it” though 😉 Do you mean:
(a) The Suggester may choose their own arbitrary value to suggest if SOME of the Permission Granted messages contain previously accepted values, as long as the Permission Granted messages recieved from a MAJORITY of peers do NOT contain previously accepted values. E.g. in the example from your reply, if D and E were still on-line, they would tell A that they had previously accepted a certain value, but, since they’re only a minority, A would be free to ignore their value and propose its own. OR do you mean:
(b) The Suggester may choose their own arbitrary value if (i) they get Permission Granted replies from a majority of peers and (ii) NONE of those replies contain any previously accepted value. E.g. your example works as you wrote if D and E are offline, but if they are online A is obliged to accept their value.
LikeLike
The rule is “If and only if Permission Granted messages from a majority of peers indicate that no suggestion has previously been accepted may a peer suggest whatever arbitrary value they choose”. Note that the rule simply states a “majority” is needed. Any majority will do. So if a peer receives messages from more than a majority, it can choose any combination of peers it wishes so long as that set of peers still constitutes a majority. Consequently, scenario (a) in your description is valid. Make sense?
LikeLike
Yes. Makes sense. And (finally) I understand the point from your first reply, that due to the possibility of dropped messages, my “b” is kind of pointless 😉
Thanks for the replies and the great explanation.
LikeLike
I’m glad to have read these comments; I think I finally get it too. However, you really ought to update some earlier content. Under the headings Achieving Consensus > Message Handling Rules, is a paragraph that very distinctly describes John’s scenario b):
“The key to Paxos’ assurance of correctness lies in the interplay between requesting permission to make suggestions and actually making those suggestions. When granting permission for a new suggestion, peers must include the highest Suggestion ID and Value they have accepted, if any, in the Permission Granted message. Once the suggesting peer has received a majority of permission grants and before making its own suggestion, the peer must first examine the previously accepted Suggestion IDs and Values contained in those grants. If any peer has previously accepted a suggestion, the Value of the new suggestion must be set to the Value corresponding to the highest Suggestion ID contained in the grant messages. If and only if no peer has previously accepted a suggestion may the suggester supply an arbitrary Value of their choosing.”
Which is then contradicted in the later paragraph that he quoted.
LikeLike
After John’s comment I thought about trying to reword the description you quoted to make it more obvious that there is only an apparent contradiction, not an actual one. The only thing I could come up with would be to say that a “minimum majority” is required but that description is already complicated enough and it seems like that would be more likely to add confusion than lessen it. Please let me know if you can think of a better way to word it; this is the best I could come up with. With respect to the point in question though, I’m not sure exactly why this trips a lot of people up (which is weird because I was one of those people) but it definitely does. Maybe it’s the fact that “more than a majority” is still a “majority” so we feel somehow obligated to apply the same restrictions an algorithm places on a “majority” to situations that are, in fact, “more than a majority”. For me, at least, the point became clearer when I started thinking in terms of dropped messages, which the algorithm was explicitly designed to support. If the algorithm only requires a majority and I have more than a majority of messages, I can arbitrarily choose to discard excess messages without violating correctness. So if I’m in the position where I have a majority of messages that allow me to do what I want plus one or more that don’t I can just pretend like those undesirable messages were dropped by the network and process the only the majority of messages that are in my favor. Ultimately, it’s a fairly subtle point that could ignored, especially since it’s difficult to take advantage of in practice without adversely impacting liveness, but it seemed worth including for the sake of completeness.
LikeLike
Hah! That’s a great way to word it, why not just copy and paste all that into it? Kidding, of course.
If I may, I would suggest a slight modification of the excerpt from Message Handling:
“… If any peer has previously accepted a suggestion, the Value of the new suggestion must be set to the Value corresponding to the highest Suggestion ID contained in the grant messages. If and only if no peer has previously accepted a suggestion may the suggester supply an arbitrary Value of their choosing.
Simply put, a peer may suggest any Value they choose if no previous suggestions have been accepted. If previous suggestions have been accepted though, the peer is forced to use the Value associated with the highest previously accepted Suggestion ID.”
To:
“… If and only if the suggesting peer receives a majority of *empty* grant messages, it is free to supply an arbitrary Value of its choosing. If, however, it cannot make a majority of *empty* grant messages, but has received grant messages from a majority of peers, **the suggesting peer must use the Value associated with the highest previously accepted Suggestion ID**.”
This could be elaborated with a quick example: Suppose a Suggester (A) in a 5 node system receives grant messages from a majority of its peers (A, B, C). A and B respond with empty granted messages whereas C responds with a grant message containing a previously accepted value, Y. Because the Suggester has received grant messages from a majority of peers, it can begin proposing a Value, but because it cannot make a majority of empty messages, it must propose Y. At this point A may wait for a response from D or E with hopes that one of them responds with an empty grant message, at which point A would be free to suggest its own value, X.
Then again, maybe I’m just beating the point too far into the ground.
And my apologies if my original comment seemed overly pragmatic. My understanding of Paxos can be almost entirely accredited to this blog article. You’ve done a terrific job of explaining it.
LikeLike
Thanks Ian. I’ve gone back and forth on this a few times and I think I’m going to leave the original wording in place. It’d be nice to elaborate on the point directly but it still seems like it would make that bit of the explanation harder to follow. It’s always a tossup on that kind of point though because people frequently disagree about whether one explanation or another is easier to understand. Fortunately though, I think the point is well covered here. The example you provided should quickly clear things up for anyone that finds my original description lacking.
LikeLike
Thanks so much. This post do help me.
LikeLike
Thank you so much for this thoughtful and articulate explanation.
LikeLike
great job
LikeLike